
The Ultimate Guide to Speech Recognition
In this ‘Ultimate Guide to Speech Recognition’, we’ll provide a brief overview of speech recognition and its importance, explore the various types and applications of speech recognition, then look towards the future.
Click any of the boxes below to jump directly to that section. You can also download a full version of the guide as a PDF, complete with additional insights, charts, and tips & tricks.
Table of Contents
PART ONE
Speech Recognition Overview
What is speech recognition?
Speech recognition is a method of translating speech to text through artificial intelligence. Speech recognition software is able to convert live or recorded audio of spoken language into text nearly instantaneously.
How speech recognition is used today
Speech recognition has rapidly become more accessible, to the point where ‘smart’ devices don’t seem as smart without some form of speech recognition.
For many, speech recognition has become so ingrained in their daily routine that asking Siri for directions or getting Alexa to play a song comes naturally. Smart devices – more specifically virtual assistants on smart devices – are among the most common uses for speech recognition today.
In the Microsoft® 2019 Voice Report, 72% of respondents indicated they have used a digital assistant like Siri, Alexa, Google Assistant, or Cortana. The use of digital assistants is likely to continue rising over time as they become more accurate and can perform more functions.
Aside from personal use, speech recognition is widely used to boost productivity in work environments. The healthcare, education, business, legal, law enforcement, and entertainment industries all benefit from speech recognition for transcription and work automation.
Speech Recognition vs. Voice Recognition
The main difference between speech recognition and voice recognition is that, for any given audio where spoken language can be heard, speech recognition identifies the words being used, whereas voice recognition identifies the speaker.
Voice recognition is generally used as a security measure for unlocking devices, but can also be used for personalization.
Speech recognition and voice recognition are sometimes used interchangeably to mean the same thing (converting speech to text), but there are slight differences between the two.
The history of speech recognition
Speech recognition is a relatively new technology, and one that continues to improve each decade. Sound recording was first made possible with the Dictaphone in 1907. Roughly 50 years later, in 1952, the first speech recognition technology emerged. This technology was named Audrey, built by Bell Labs – and it was able to recognize speech for single digits from zero to nine.
Development for speech recognition technology took major leaps nearly every decade. 10 years after Audrey was created, IBM demonstrated their own speech recognition device: Shoebox. Shoebox was also able to recognize single digits from zero to nine, but it could also recognize a few English command words, such as “plus” and “minus”.
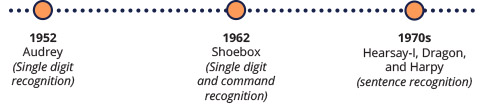
The next leaps in speech technology were largely the result of research at Carnegie Mellon University, where three systems – Hearsay-I, Dragon, and Harpy – were developed. Harpy was created with learnings from the two prior models (Hearsay-I and Dragon) and was the most advanced speech recognition system to date. Harpy had a limited vocabulary but was able to recognize sentences. The Dragon system has continued development and was later acquired by Nuance Communications to become one of the most widely used professional speech recognition options today.
Speech recognition continued to develop as more elements of speech were analyzed. During and beyond the 1980s, speech recognition models were able to recognize more words and even reference context and grammar to improve recognition accuracy.
The greatest improvements to speech recognition technology today were made alongside two major technological advancements: PCs and mobile phones. PCs and mobile phones allowed for more applications of speech recognition for personal use, expanding the possibilities of speech recognition and driving further improvements.
How speech recognition accuracy is measured
Speech recognition accuracy is measured by word error rate. Word errors can either occur from an unrecognized word or phrase, an incorrectly recognized word or phrase, or a contextually incorrect word or phrase.
There are several instances where words or phrases will be entirely unrecognizable or incorrectly recognized by speech recognition software. Some of the most common causes are a mumbled or muffled dictation or proper nouns outside of the speech engine’s dictionary. Speech recognition software generally has two courses of action in a case like this – either return a phonetically similar word/phrase or, in the case of virtual assistants like Siri, prompt the dictator to try again.
A contextually incorrect word might be recognizing ‘colon’ as the punctuation mark (:) rather than the organ, or recognizing ‘to’ as the number ‘2’. There are various other cases and examples of incorrect contextual recognition which all can contribute to a higher word error rate.
Some remedies for incorrect recognition are machine learning and specialized speech recognition. A healthcare-specific speech recognition solution might be able to better handle the ‘colon’ example from earlier. It would also better handle healthcare terminology, such as medications, where general-purpose speech recognition might struggle.
Accuracy is a key factor in determining speech recognition proficiency, but return time should also be considered. Return time is the amount of time it takes for the speech recognition software to recognize and transcribe speech into text. Highly accurate speech recognition that takes more time to transcribe than a human might not be as useful as 95% accuracy with a return time of a few seconds.

Industries that use speech recognition
Speech recognition is used in a variety of industries, including healthcare, education, legal, law enforcement, business, and entertainment. We cover this in more detail in part four.
Two main functions of speech recognition – speech-to-text and voice commands – can add efficiency in nearly any profession, especially those that deal in computer work.
In any job that involves a lot of typing, like some positions in the fields listed above, speech-to-text can save time as a supporting software or even as a substitute for typing. The average typing speed is only 41 words per minute (wpm), while the average conversational speaking speed is triple that at 120 wpm.
Those in a role that involves typing daily will often have above-average typing speeds, but only the most skilled typists can even come close to the average speaking speed.
Speech recognition is also heavily relied upon in customer service (especially for business), where a virtual assistant guides a caller through a menu of options.

Want a version of this guide to keep on your computer?
Download a full version of this guide for more insights.
PART TWO
The Importance of Speech Recognition
There are two key benefits of speech recognition:
- Time savings
- Higher accessibility
Time savings and overall efficiency are a large part of why speech recognition has been adopted in so many industries.
Speech recognition is mutually beneficial for businesses and employees because it leads to more automation, and as a result, higher efficiency.
People speak faster than they type and that alone can be a source of huge time savings.
As soon as you start incorporating voice-enabled shortcuts (either with virtual assistants or dedicated speech recognition software), you can save even more time.
It also saves time in activities outside of work. The less time you spend manually typing or navigating on a device, the more time you have for everything else.
Speech recognition offers accessibility. With the proper equipment, it can be used without a keyboard or mouse. This gives speech technology a leg up over traditional data entry and can lead to further efficiency.
Speech recognition also offers accessibility for personal tasks with virtual assistants. Virtual assistants like Siri and Alexa make it easy to write down a note, play music, or make a call from your car or in your home. With the help of a voice assistant, you might be able to better multi-task, stay organized, and get away from your phone.
Why doesn’t everyone use speech recognition?
Even with accuracy rates of 95%+, there is some reluctance to completely rely on speech recognition. 5% may not seem like much, but when dealing with numbers or recording valuable information, any mistake can be detrimental.
Most recognized text will still need some level of review. This is still faster than manually typing in most cases, but some individuals and organizations are still hesitant towards speech recognition.
As speech recognition technology continues to make advancements, each benefit will be further amplified. That means more time saved and even greater accessibility. With these improvements, reluctance towards speech recognition will also likely decrease.
PART THREE
Types of Speech Recognition
Speech recognition has become integrated with phones, cars, and nearly any device connected to the internet. With such a wide range of applications, it’s only natural that different types and uses for speech recognition have arisen.
The core functionality of speech recognition is the same across all applications: recognize words, phrases, and numbers. But, for each application of speech recognition, the objective is slightly different and more might be requested from the speech recognition software.
For example, some software might transcribe recognized words to text (think speech-to-text) while another might simply use the recognition to perform an action (think virtual assistant).
Most speech recognition that we’re familiar with today falls under the umbrella of Automated Speech Recognition (ASR). An even more advanced subcategory of ASR Is natural language processing (NLP). The virtual assistants that we’re familiar with often incorporate NLP to more accurately recognize speech.
Most popular speech recognition software
The most popular speech recognition software is often free. Google’s speech-to-text tool, speech-to-text on operating systems like Mac and Windows®, and virtual assistants are all built-in features with high accuracy and functionality. There are limitations for these free options, but they’re convenient and often do a good enough job (depending on what they’re being used for).
Let’s take a deeper look at the technology behind some of these major speech platforms because their inner workings are more connected than you might expect.
Free speech recognition software
Siri is arguably the most common form of speech recognition today, because it comes pre-installed on the most prominent smartphone on the market – the iPhone®. Siri was introduced in 2011 with the iPhone® 4S, making it not only the most popular modern virtual assistant, but the first.
Siri’s voice engine was developed by Nuance Communications who, if you’ll remember, acquired one of the earliest speech recognition systems: Dragon.
Recently, Microsoft® purchased Nuance Communications for $19.7 billion. Microsoft® has its own virtual assistant, Cortana, which is available on Microsoft® phones and devices that operate on Windows®. This purchase could mean two of the most popular virtual assistants – and several of the most trusted paid speech recognition solutions – would be powered by the same (or similar) voice engines.
The third virtual assistant of note is Amazon’s Alexa. Alexa is powered by Amazon’s own voice recognition engine and comes pre-installed on nearly all modern Amazon devices, including tablets, speakers, smartphones, and streaming devices.
Google has both speech-to-text tool built directly into their search engine and a virtual assistant that comes paired with Google devices. Google’s speech-to-text tool works on mobile and desktop devices with any operating system within their search engine. The tool is also available within Google Chrome in their word processing software, Google Docs. Much like Amazon, Google offers several smart devices with its own virtual assistant.
Paid speech recognition software
Free speech recognition software is dominated by some of the biggest names in technology and is advancing quickly. However, free software isn’t always suited for professional work, which is definitely the case with speech recognition.
Some of the more advanced use cases for speech recognition, such as healthcare dictation, legal and law transcription, and data entry, require speech recognition built for that purpose. Healthcare speech recognition will operate differently from legal speech recognition, for example.
Although the major players in the free speech recognition market still have some stake in professional speech recognition (especially with the recent Microsoft® purchase of Nuance Communications), there are a few different companies at the top of the paid market.
Nuance Communications is likely the biggest name in the paid speech market with its suite of Dragon products, built for the previously mentioned industries (healthcare, law enforcement, and legal) as well as a general-purpose paid solution: Dragon NaturallySpeaking.
Within the healthcare market, there are two other major speech recognition vendors: Dolbey and 3M.
Amazon Transcribe is also built with Amazon’s speech recognition engine with a pricing model based on seconds of audio transcribed. The pricing and design for this software make it ideal for clients that need large quantities of audio transcribed on a consistent basis.
Amazon also has software intended for the healthcare industry with Amazon Transcribe Medical.
IBM Watson is an incredibly accurate speech recognition platform designed for enterprises. IBM Watson can be used for simple speech-to-text, but it can also be used to transcribe calls from call centers or as the speech engine that behind virtual assistants on support calls.
Get a copy to share with your friends
Download the full version of this guide for more insights.
PART FOUR
Applications of Speech Recognition
As we’ve explored, some of the most common applications of speech recognition are virtual assistants, devices that can recognize your voice, and speech-to-text.
Some of the more niche, but equally important, applications of speech recognition are translation and custom voice commands.
Google Translate is an excellent example of speech recognition for translation; with support for over 100 languages, users can speak into their device’s microphone and easily get a translation for their preferred language. Google has implemented a conversational translation feature for the Google Translate app, which allows people speaking two different languages to more easily communicate. Google will pick up on the language and speaker, then translate to the other language being spoken.
With the wide set of applications for speech recognition at work (which we’ll go into in just a minute), efficiency has become one of the driving factors for improvements and feature updates to speech recognition software. A key addition to speech recognition in the past few decades is custom voice commands. With voice commands, an end user can order their device to perform an action or series of actions with just a word or phrase.
For example, someone might build a ‘start my day’ command on their computer, which would open a series of applications they need to start their day – maybe the weather app, their email inbox, and the homepage of a news site. As soon as this these commands are applied to work or any sort of repetitive task, they can be a huge timesaver, made even more accessible by voice activation.
Speech recognition for work
Speech recognition is used to make work more efficient or to take over work responsibilities in several industries, but especially in healthcare, law enforcement, business, legal, entertainment, and education.
Healthcare
The primary use for speech recognition in healthcare is to streamline the documentation process. Physicians that interact with patients must record notes for the patient visit to provide a status update and guide towards next steps. These notes are what make up documentation, which is a standard process for physicians. Healthcare specialties that don’t involve direct interaction with patients also require some level of reporting.
The documentation process became more involved with the introduction of electronic health records. Some early approaches were writing notes or dictating directly into a voice recorder, then having a third party convert those notes into a more legible version. Transcriptionists are still relatively common in the medical practice, but speech recognition has proven to be a more efficient approach.
Law Enforcement
Law enforcement is similar to healthcare in that encounters must be recorded. Incident forms and police reports must be completed as a standard procedure.
Completing this paperwork can be overwhelming, but is made more manageable with speech recognition. Law enforcement professionals can record their notes either from a mobile device, at home, or in the office with the use of speech recognition. This can clear up time that would otherwise be spent doing paperwork for other work responsibilities or personal time.
Business
Speech recognition for business is generally used for three purposes: customer service, transcription, and data entry.
Many large businesses now use digital operators that effectively work the same as a virtual assistant. These operators assist callers as they navigate through an option menu with their voice. Speech recognition has completely changed customer service and can allow businesses to reduce their staff and save money.
Meeting transcription is another common application for speech recognition in business. Instead of frantically jotting down notes, speech recognition can simply transcribe a full meeting. More advanced solutions are even able to separate the transcription by who is talking, combining the power of voice recognition and speech recognition.
Data entry can be optimized or even automated with the use of speech recognition. Many solutions are able to handle large numerical values which can be quicker and more reliable than manual entry – but the key benefit of speech recognition for data entry is the use of voice commands to run functions or macros in database and data processing tools. You can more quickly run queries or perform repetitive functions with a simple voice command, making data entry more efficient and accessible.
Legal
Speech recognition can assist in filling documents in preparation for court proceedings and building court transcripts.
Several documents need to be prepared for court, including memos and briefs. These documents take quite a bit of time to prepare manually – which is why the task is often allocated to paralegals or legal scribes. Instead of allocating the work to another person, it can instead be expedited through speech recognition.
Speech recognition is also making its mark on court transcripts. You’ve almost certainly seen court reporting in practice, whether it’s in a courtroom or on TV – someone typing quickly on a device transcribing dialogue within the courtroom. It’s a tough job that requires keen attention, a legal vocabulary, and fast typing speeds. Court reporters are also in short supply, but the demand continues to rise.
Some courts now utilize speech typing, which involves the court reporter repeating dialogue directly into a speech device as it is spoken. As speech recognition technology develops, we may see software that utilizes both speech and voice recognition that recognizes speech and separates recognized text based on the speaker.
Entertainment
One key factor of modern televised or digital entertainment, especially live broadcasts, is closed captioning. Closed captioning is generally provided by a stenographer or generated by automatic speech recognition.
Live broadcasting is fast-paced and requires fast, accurate stenographers. As with legal speech recognition, finding stenographers for this type of work is becoming more of a challenge. Speech recognition is an affordable alternative.
Although speech recognition for closed captioning is more readily available than stenographers, it must reach a similar level of accuracy and speed. This can be difficult to match for live broadcasts, which is why closed captioning speech recognition tends to be more expensive.
Education
Closed captioning can be equally important for recorded videos. In education, speech recognition can be used to transcribe videos. In fact, with so much educational content on YouTube, speech recognition is already being used heavily – YouTube videos can receive automated closed captioning with technology that continues to improve. Some educators and those in other fields have started uploading videos to YouTube for quick, free transcription.
Speech recognition can also be used for lecture transcription, which can be a useful way to keep notes.
PART FIVE
The Future of Speech Recognition
As speech recognition technology continues to develop, it will only become more ingrained in our daily lives. Technology that improves efficiency catches the eye of businesses and makes its way into our personal lives.
Speech recognition will only become more compelling as accuracy continues to improve and more uses for speech recognition are developed. Speech and voice recognition technology is already advanced, but improvements to accuracy and speed will take it to the next level.
The next frontier is speech recognition accuracy approaching, or maybe even surpassing human accuracy in transcription. Is that even possible? It remains to be seen.
Although there were leaps in accuracy for the past several decades, progress has slowed and improving average accuracy by even a fraction of a percent is a major milestone.
But many of the ideas that once seemed futuristic have already been realized – we have speech recognition in cars, at home, and even in the palm of our hand. We’ll certainly continue to see improvements in speech recognition accuracy, but how far can we move that needle?
It might not be too far-fetched to believe that speech recognition will one day surpass human accuracy, but it also might simply not happen.
The future of speech recognition is exciting – and as speech technology develops, our lives might see more major shifts in the way we do things. Keep an eye out for new applications of speech recognition and watch as one of the most universal technologies continues to grow.
Now that you have a better understanding of speech recognition, get out there and start improving your efficiency in your work and daily life.